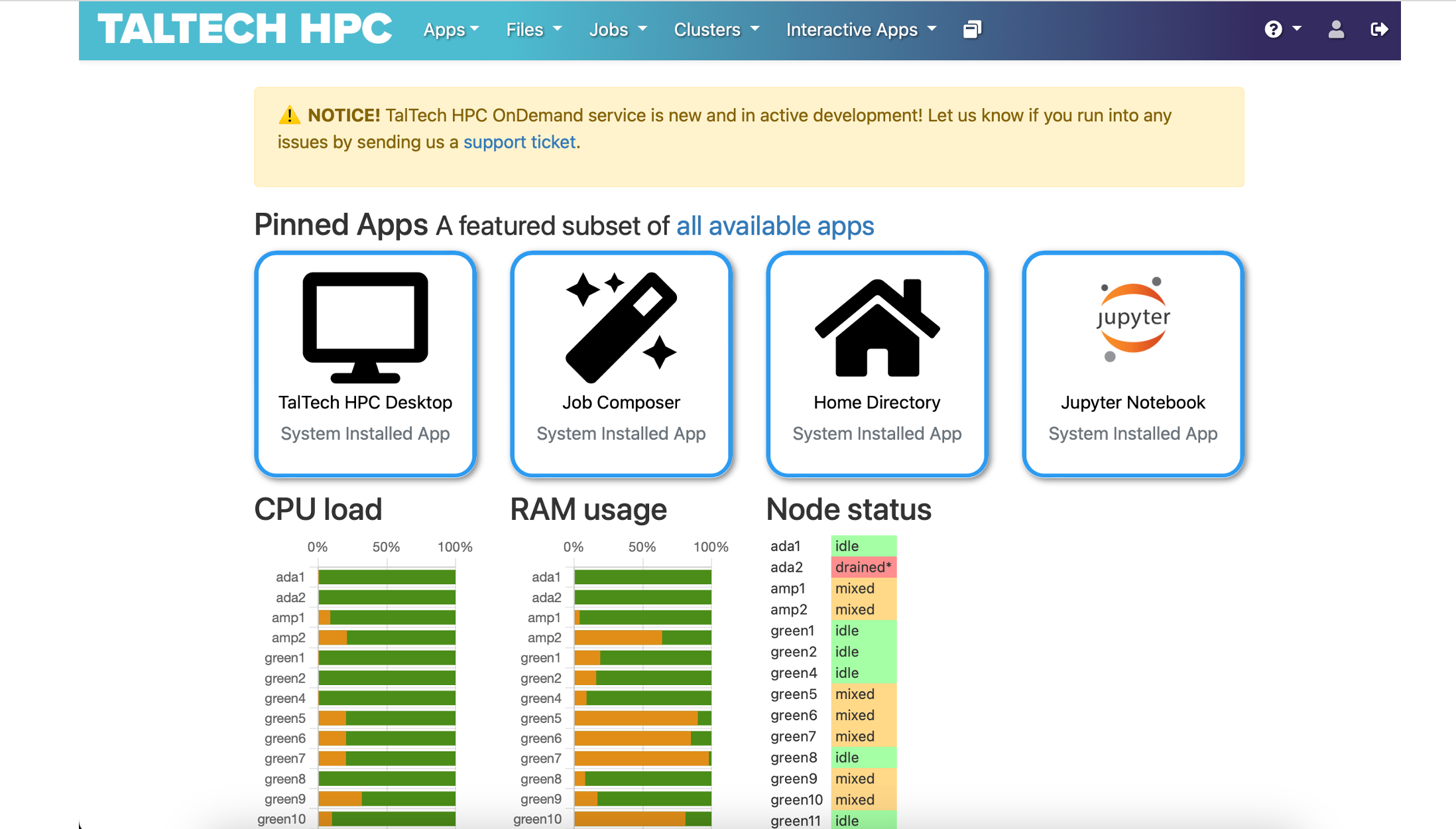
Quickstart: Cluster#
Accessing the cluster#
NB! To access the cluster, user must have an active Uni-ID account. For people who are neither students nor employees of Taltech Uni-ID non-contractual account should be created by the head of a structural unit.
To get access to HPC contact us by email (hpcsupport@taltech.ee) or Taltech portal. We need the following information: uni-ID (typically 6 letters), which this you will get basic access which can be used for small calculations and to get familiar with the system (limit approx. 10 Euro per quarter year). For larger calculations, we need to know the department and project that covers costs.
The cluster is accessible from inside the university and from major Estonian network providers. If you are traveling (or not in one of the major networks), the access requires FortiVPN (for OnDemand session and ssh command).
To access the cluster base.hpc.taltech.ee via a browser with a graphical, menu-based environment use desktop session on ondemand.hpc.taltech.ee
Another option is SSH (the Secure SHell), available by command ssh in Linux/Unix, Mac and Windows-10. A PuTTY guide for Windows users (an alternative SSH using a graphical user interface (GUI)) is here.
For using graphical applications add the -X, and for GLX (X Window System) forwarding additionally the -Y switch,:
where uni-ID should be changed to user's uni-ID.
NB! The login-node is for some light interactive analysis. For heavy computations, request a (interactive) session with the resource manager SLURM or submit job for execution by SLURM sbatch script!**
We strongly recommend to use SSH-keys for logging to the cluster with ssh command. How to get SSH keys.
Structure and file tree#
By accessing the cluster, the user gets into home directory or $HOME (/gpfs/mariana/home/$USER/).
In the home directory, the user can create, delete, and overwrite files and perform calculations (if slurm script does not force program to use $SCRATCH directory). The home directory is limited in size of 500 GB and backups are performed once per week.
The home directory can be accessed from console or by GUI programs, but it cannot be mounted. For mounting was created special smbhome and smbgroup folders (/gpfs/mariana/smbhome/$USER/ and /gpfs/mariana/smbgroup/, respectively). More about smb folders can be found here.
Some programs and scripts suppose that files will be transfer to $SCRATCH directory at compute node and calculations will be done there. If job will be killed, for example due to the time limit back transfer will not occur. In this case, user needs to know at which node this job was running (see slurm-$job_id.stat), to connect to exactly this node (in example it is green11). $SCRATCH directory will be in /state/partition1/ and corresponds to jobID number.
Please note that the scratch is not shared between nodes, so parallel MPI jobs that span multiple nodes cannot access each other's scratch files.
Running jobs with SLURM#
SLURM is a management and job scheduling system at Linux clusters. More about SLURM quick references.
Examples of slurm scripts are usually given at the program's page with some recommendations for optimal use of resources for this particular program. List of the programs installed at HPC is given at our software page.
The most often used SLURM commands are:
srun- to start a session or an application (in real time)sbatch- to start a computation using a batch file (submit for later execution)squeue- to check the load of the cluster and status of jobssinfo- to check the state of the cluster and partitionsscancel- to delete a submitted job (or stop a running one).
For more parameters see the man-pages (manual) of the commands srun, sbatch, sinfo and squeue. For example:
Requesting resources with SLURM can be done either with parameters to srun or in a batch script invoked by #SBATCH. Unless otherwise specified, 1GB/thread will be used and the job will run for 10 minutes. More about partitions and their limits.
Running an interactive session longer than default 10 min. (here 1 hour):
This logs you into one of the compute nodes, there you can load modules and run interactive applications, compile your code, etc.
With srun is reccomended to use CLI (command-line interface) instead of GUI (Graphical user interface) programs if it is possible. For example, use octave-CLI or octave instead of octave-GUI.
Running a simple non-interactive single process job that lasts longer than default 4 hours (here 5 hours):
NB! Environment variables for OpenMP are not set automatically, e.g.
would not set OMP_NUM_THREADS to 28, this has to be done manually. So usually, for parallel jobs it is recommended to use scripts for sbatch.
Below is given an example of batch slurm script (filename: myjob.slurm) with explanation of the commands.
#!/bin/bash
#SBATCH --partition=common ### Partition
#SBATCH --job-name=HelloOMP ### Job Name -J
#SBATCH --time=00:10:00 ### Time limit -t
#SBATCH --nodes=4 ### Number of Nodes -N
#SBATCH --ntasks-per-node=7 ### Number of tasks (MPI processes)
#SBATCH --cpus-per-task=4 ### Number of threads per task (OMP threads)
#SBATCH --account=project_CHANGEME ### CHANGE THIS TO YOUR PROJECT/COURSE
#SBATCH --mem-per-cpu=100 ### Min RAM required in MB
#SBATCH --array=13-18 ### Array tasks for parameter sweep
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK ### setup environment
module load gcc ### setup environment
./hello_omp $SLURM_ARRAY_TASK_ID ### only for arrays, setup output files with system information
srun -n 28 ./hello_mpi ### run program
In this example are listed some of the most common submission parameters. There are many other possible options, moreover, some of the options listed above are not useful to apply together. Here can be found descriptions of the variables used inside SLURM/SBATCH and more examples of SLURM scripts with more detailed explanations.
The job is then submitted to SLURM by
and will be executed when the requested resources become available.
Output of applications and error messages are by default written to a slurm-$job_id.out file. More about SLURM finished job statistics.
Node features for node selection within a partition using --constraint=:
| feature | what it is |
|---|---|
| A100-40 | has A100 GPU with 40GB |
| A100-80 | has A100 GPU with 80GB |
| L40 | has L40 GPU with 48GB |
| nvcc80 | GPU has compute capability 8.0 (A100, L40) |
| nvcc89 | GPU has compute capability 8.9 (L40) |
| nvcc35 | GPU has compute capability 3.5 (K20Xm, A100, L40) |
| zen2 | AMD Zen CPU architecture 2nd generation (amp1) |
| zen3 | AMD Zen CPU architecture 3rd generation (amp2) |
| zen4 | AMD Zen CPU architecture 4th generation (ada*) |
| avx512 | CPU has avx512 (skylake, zen4) |
| skylake | Intel SkyLake CPU architecture (green*) |
| sandybridge | Intel SandyBridge CPU architecture (mem1tb, viz) |
| ib | InfiniBand network interface |
SLURM accounts#
In SLURM exist accounts for billing, these are different from the login account!
Each user has his/her own personal SLURM-account, which will have a small limit (currently 10 Euro per quarter). For larger calculations user should have at least one project account. SLURM user-accounts start with user_ and project accounts with project_ (legacy project accounts start with acct_) and course accounts with course_, followed by uniID/projectID/supervisor-name/courseID.
You can check which SLURM accounts you belong to, by:
When submitting a job, it is important to use the correct SLURM-account --account=SLURM-ACCOUNT, as this is connected to the financial source.
Use the command-line parameter to srun/sbatch:
to your scripts.
Monitoring jobs & resources#
Monitoring a job on the node#
Status of a job#
User can check the status his jobs (whether they are running or not, and on which node) by the command:

Load of the node#
User can check the load of the node his job runs on, status and configuration of this node by command
the load should not exceed the number of hyperthreads (CPUs in SLURM notation) of the node.
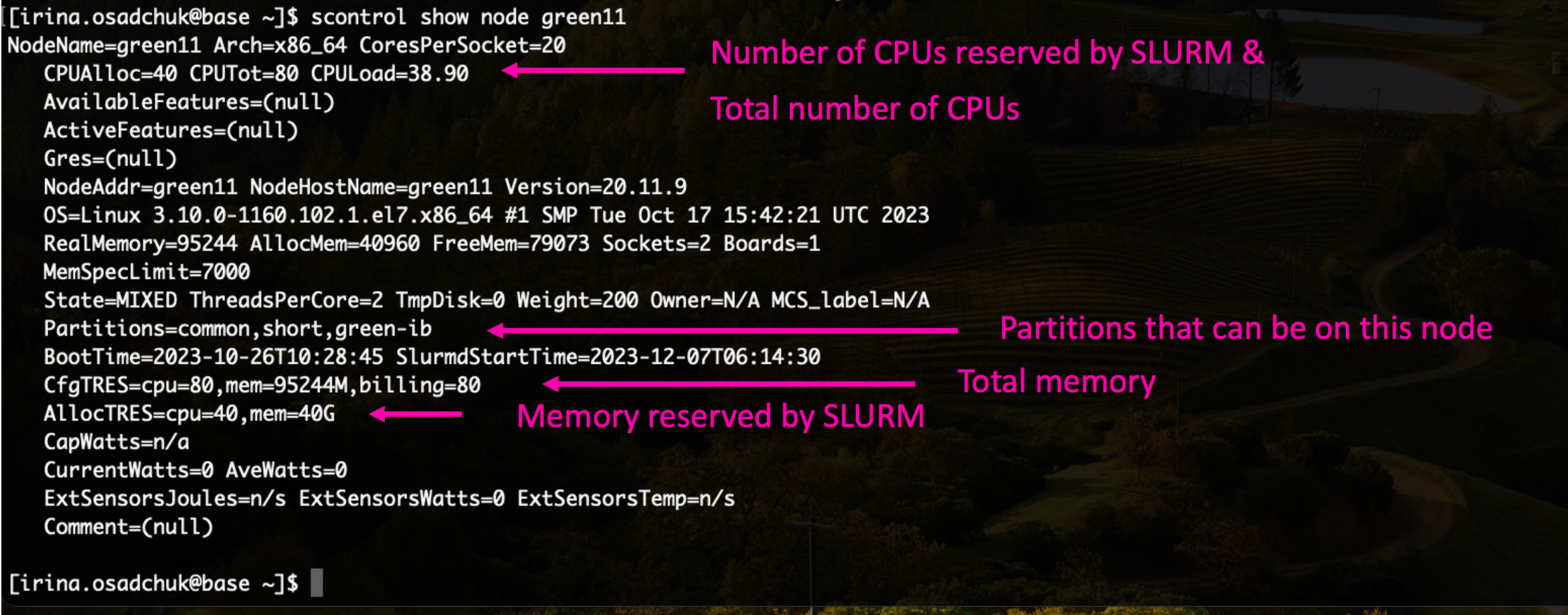
In case of MPI parallel runs statistics of several nodes can be monitored by specifying nodes names. For example:
Monitoring with interactive job#
It is possible to submit a second interactive job to the node where the main job is running, check with squeue where your job is running, then submit
Note that there must be free slots on the machine, so if you cannot use -n 80 or --exclusive for your main job (use -n 79).
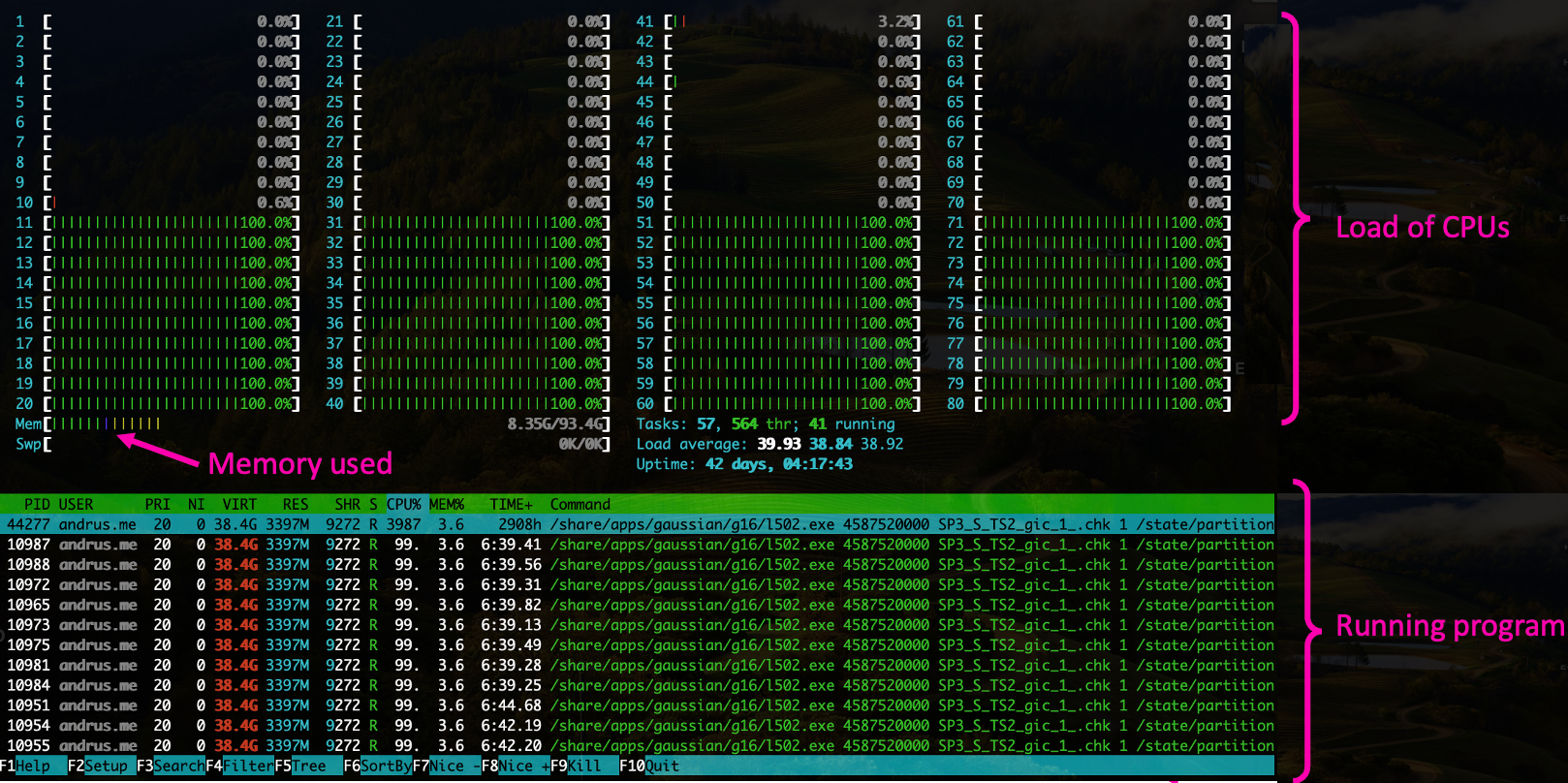
Press q to exit.
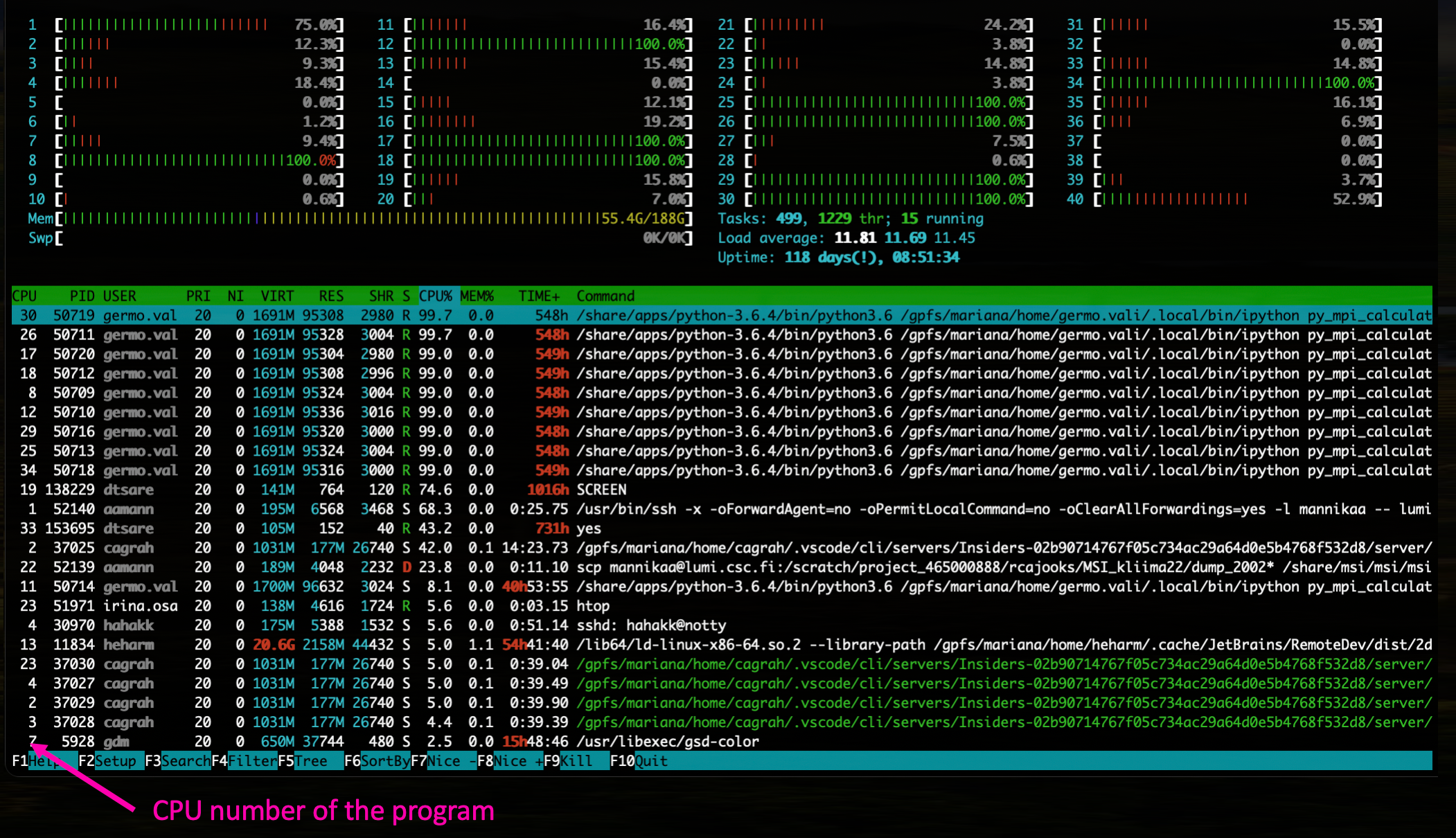
You can also add a column that shows the CPU number of the program
For Linux F1-F10 keys should be used, for Mac - just click on the corresponding buttons.
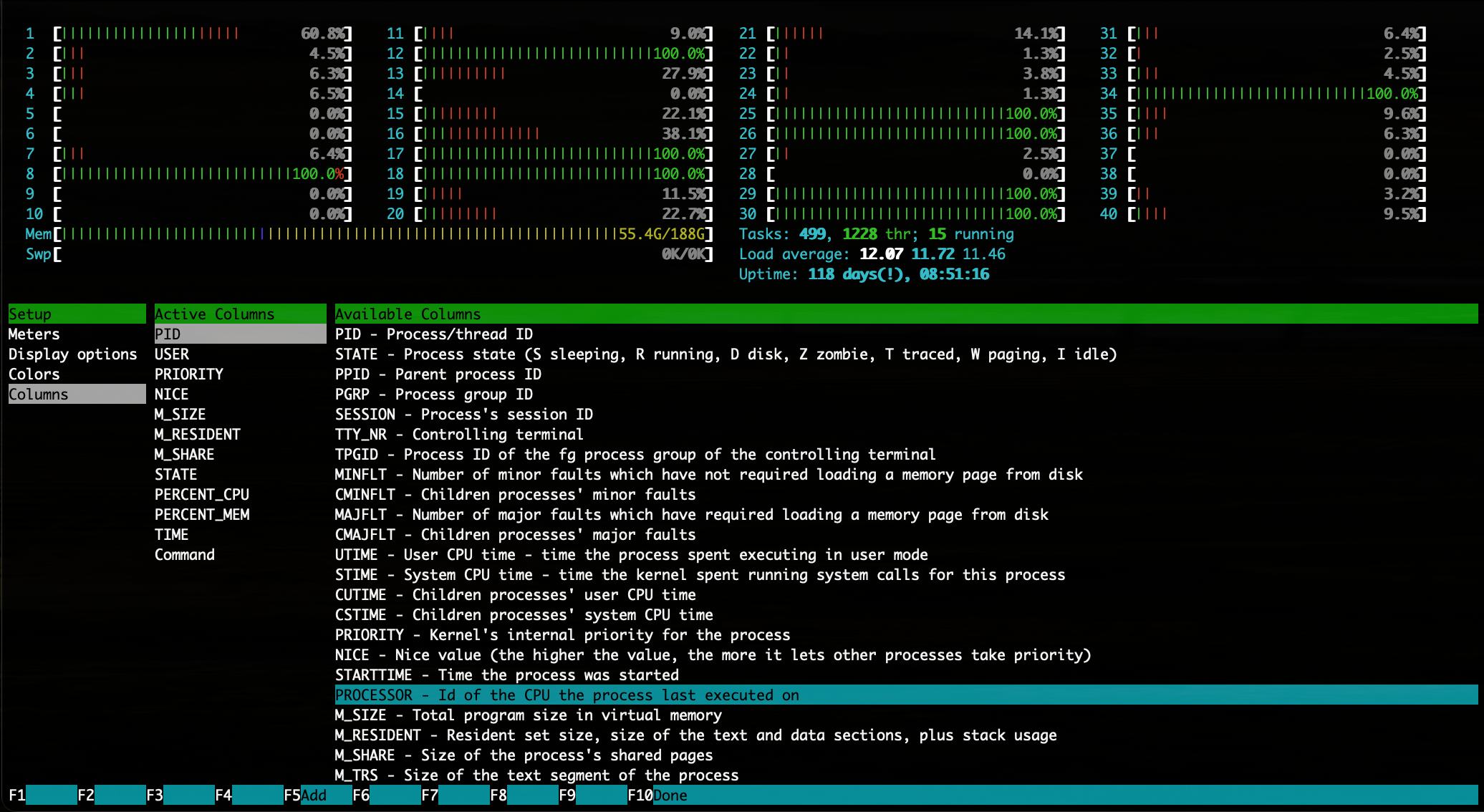
Will appear a new column, showing the CPU number of the program.
Monitoring jobs using GPUs#
Log to amp or amp2. Command:
shows the GPU IDs allocated to your job.
GPUs load can be checked by command:
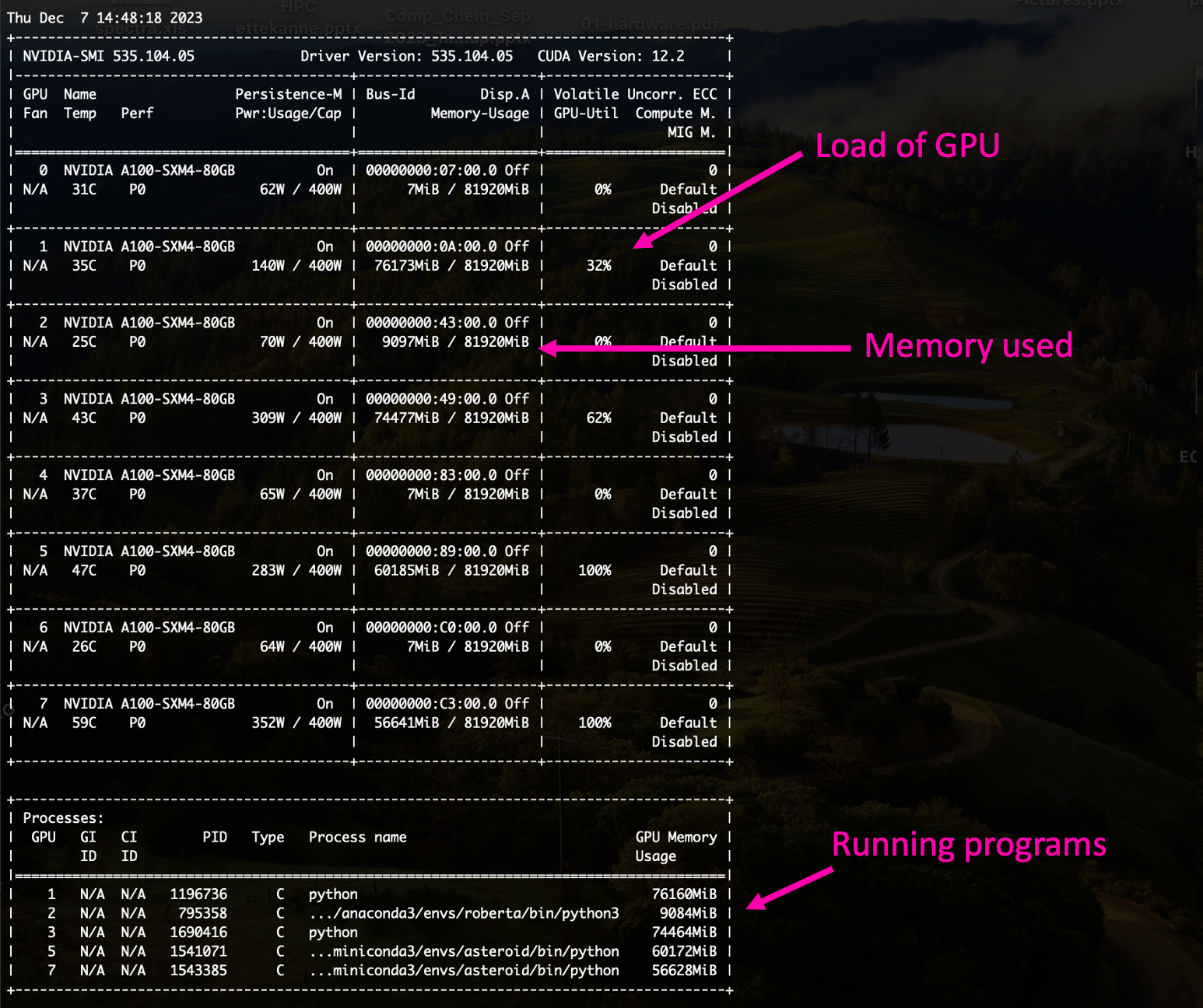
Press control+c to exit.
Another option is to logging to amp or amp2, check which GPUs are allocated to your job, and give command:
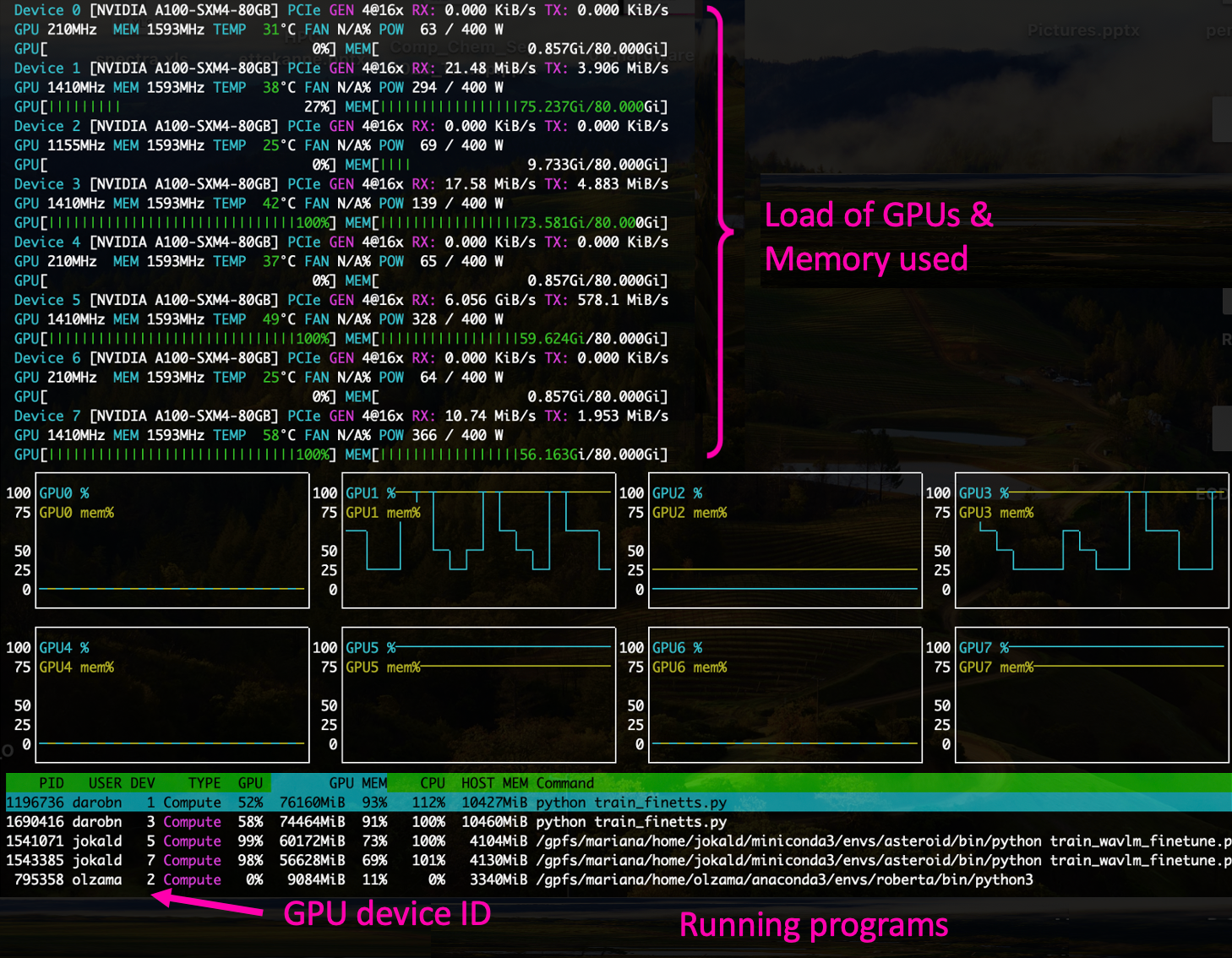
Press q to exit.
An alternative method on Linux computers, if you have X11. Logging to base/amp with --X key:
then submit your main interactive job
and start an xterm -e htop & in the session.
In sbatch the option --x11=batch can be used, note that the ssh session to base needs to stay open!
Monitoring resource usage#
Default disc quota for home (that is backed up weekly) is 500 GB and for smbhome (that is not backed up) -- 2 TB per user. For smbgroup there is no limits and no backup.
The easiest way to check your current disk usage is to look at the table that appears when you log in to HPC.

You can also monitor your resource usage by taltech-lsquota.bash script and sreport command.
Current disk usage:
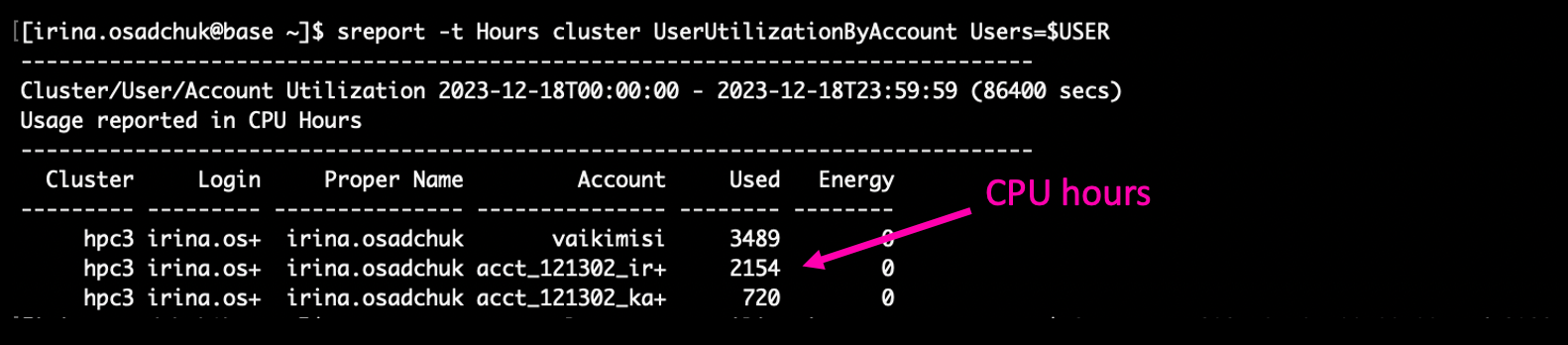
CPU usage during last day:
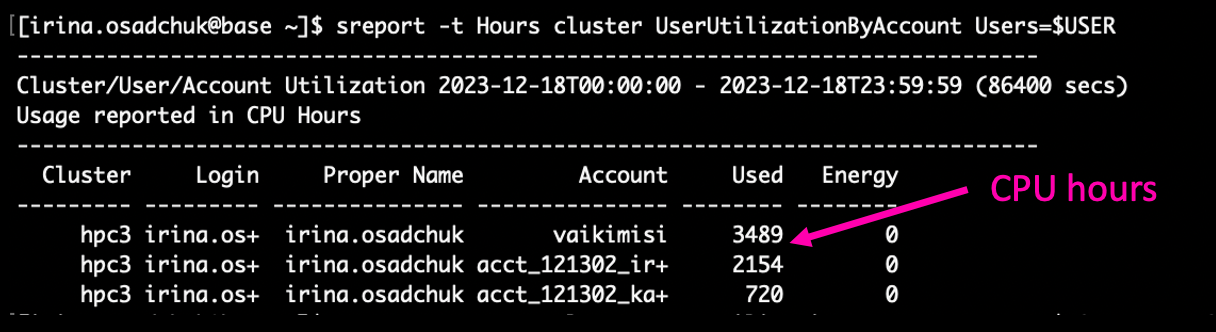
CPU usage in specific period (e.g. since beginning of this year):
sreport -t Hours cluster UserUtilizationByAccount Users=$USER start=2024-01-01T00:00:00 end=2024-12-31T23:59:59
Where start= and end= can be changed depending on the desired period of time.

For convenience, a tool taltech-history was created, by default it shows the jobs of the current month, use taltech-history -a to get a summary of the useh hours and costs of the current month.
Copying data to/from the clusters#
Since HPC disk quota is limited, it is recommended to have your own copy of important calculations and results. Data from HPC can be transferred by several commands: scp, sftp, sshfs or rsync.
-
scpis available on all Linux systems, Mac and Windows10 PowerShell. There are also GUI versions available for different OS (like PuTTY).Copying to the cluster with
scp:scp local_path_from_where_copy/file uni-id@base.hpc.taltech.ee:path_where_to_save
Copying from the cluster with
scp:scp uni-id@base.hpc.taltech.ee:path_from_where_copy/file local_path_where_to_save
Path to the file at HPC can be checked by
pwdcommand. -
sftpis the secure version of theftpprotocol vailable on Linux, Mac and Windows10 PowerShell. This command starts a session, in which files can be transmitted in both directions using thegetandputcommands. File transfer can be done in "binary" or "ascii" mode, conversion of line-endings (see below) is automatic in "ascii" mode. There are also GUI versions available for different OS (FileZilla, gFTP and WinSCP (Windows))sftp uni-id@base.hpc.taltech.ee
-
sshfscan be used to temporarily mount remote filesystems for data transfer or analysis. Available in Linux. The data is tunneled through an ssh-connection. Be sware that this is usually not performant and can creates high load on the login node due to ssh-encryption.sshfs uni-id@base.hpc.taltech.ee:remote_dir/ /path_to_local_mount_point/ -
rsynccan update files if previous versions exist without having to transfer the whole file. However, its use is recommended for the advanced user only since one has to be careful with the syntax.



SMB/CIFS exported filesystems#
One of the simple and convenient ways to control and process data based on HPC is mounting. Mounting means that user attaches his directory placed at HPC to a directory on his computer and can process files as if they were on this computer. These can be accessed from within university or from EduVPN.
Each user automatically has a directory within smbhome. It does not match with $HOME directory, so calculations should be initially done at smbhome directory to prevent copying or files needed should be copied from home directory to the smbhome directory by commands:
pwd ### look path to the file
cp path_to_your_file/your_file /gpfs/mariana/smbhome/$USER/ ### copying
To get a directory for group access, please contact us (a group and a directory need to be created).
The HPC center exports two filesystems as Windows network shares:
| local path on cluster | Linux network URL | Windows network URL |
|---|---|---|
| /gpfs/mariana/smbhome/$USER | smb://smb.hpc.taltech.ee/smbhome | \\smb.hpc.taltech.ee\smbhome |
| /gpfs/mariana/smbgroup | smb://smb.hpc.taltech.ee/smbgroup | \\smb.hpc.taltech.ee\smbgroup |
| /gpfs/mariana/home/$USER | not exported | not exported |
This is the quick-access guide, for more details, see here
Windows access#
The shares can be found using the Explorer "Map Network Drive".
From Powershell:
Linux access#
On Linux with GUI Desktop, the shares can be accessed with the nautilus browser.
From commandline, the shares can be mounted as follows:
you will be asked for "User" (which is your UniID), "Domain" (which is "INTRA"), and your password.
To disconnect from the share, unmount with
Special considerations for copying Windows - Linux#
Microsoft Windows is using a different line ending in text files (ASCII/UTF8 files) than Linux/Unix/Mac: CRLF vs. LF When copying files between Windows-Linux, this needs to be taken into account. The FTP (File Transfer Protocol) has ASCII and BINARY modes, in ASCII-mode the line-end conversion is automatic.
There are tools for conversion of the line-ending, in case the file was copied without line conversion: dos2unix, unix2dos, todos, fromdos, the stream-editor sed can also be used.
Backup#
There are 2 major directories where users can store data:
/gpfs/mariana/home/default home directory which is limited to 500GB and is backed up, excluding specific directories:[**/.cache/**, **/.vscode*, **/.npm/**, **/.nvm/**, **/anaconda/**, **/anaconda3/**, **/miniforge3/**, **/.conda/**, **/miniconda3/**, **/cuda/**, **/.env*, **/*venv*/, **/*envs*/, **/.singularity/, **/.local/**]./gpfs/mariana/smbhome/has a limit of 2TB and is not backed up.
The home directory is meant for critical data like configurations and scripts, whereas smbhome is meant for data.
The backup will run weekly. If the home directory is larger than 500GB [usage is displayed upon login to the cluster] it will not be backed up.
If your home directory is larger than 500G please move the data to smbhome.
At HPC are installed programs with varying licence agreement. To use some licensed programs (for example, Gaussian), the user must be added to the appropriate group. For this contact us email (hpcsupport@taltech.ee) or Taltech portal. More about available programs and licenses can be found at software page.